

Text settings
Story text
SmallStandardLargeStandardWideStandardOrange
* Subscribers only
Learn more
Google launched its Gemma 4 open models this spring, promising a new level of power and performance for local AI. Google’s take on edge AI could be getting even faster already with the release of Multi-Token Prediction (MTP) drafters for Gemma. Google says these experimental models leverage a form of speculative decoding to take a guess at future tokens, which can speed up generation compared to the way models generate tokens on their own.
The latest Gemma models are built on the same underlying technology that powers Google’s frontier Gemini AI, but they’re tuned to run locally. Gemini is optimized to run on Google’s custom TPU chips, which operate in enormous clusters with super-fast interconnects and memory. A single high-power AI accelerator can run the largest Gemma 4 model at full precision, and quantizing will let it run on a consumer GPU.
Gemma allows users to tinker with AI on their hardware rather than sharing all their data with a cloud AI system from Google or someone else. Google also changed the license for Gemma 4 to Apache 2.0, which is much more permissive than the custom Gemma license Google employed for previous releases. However, there are inherent limitations in the hardware most people have to run local AI models. That’s where MTP comes in.
LLMs Gemma (or Gemini) generate tokens autoregressively—that is, they produce one token at a time based on the previous token. Each one takes just as much computing work as the last one, regardless of whether the token is just a filler word in an output or a key piece of information in a complex logical problem.
The problem with rolling your own AI is that your system memory probably isn’t very fast compared to the high bandwidth memory (HBM) used in enterprise hardware. As a result, the processor spends a lot of time moving parameters from VRAM to compute units for each token, and compute cycles are going unused during this process.
Gemma 4 26B on a NVIDIA RTX PRO 6000. Standard Inference (left) vs. MTP Drafter (right) in tokens per second. Same output quality, half the wait time.
MTP uses that time to bypass the heavy model and generate speculative tokens with the lightweight drafter. While the draft models are smaller (just 74 million parameters in Gemma 4 E2B), they’re also optimized in several ways to speed up speculative token generation. For example, the drafter s the key value cache (essentially the LLM’s active memory) so it doesn’t need to recalculate context the main model has already worked out. The E2B and E4B drafters also use a sparse decoding technique to narrow down clusters of ly tokens.
The draft tokens are not necessarily good predictions, of course. They are verified by the target model (Gemma in this case) in parallel. If the model agrees, the entire sequence is accepted in one forward pass. Along with this process, the larger model also generates an additional token normally. So the system can produce tokens from the draft sequence and a newly generated token in parallel in the time it used to take to generate a single new token. If you want more detail, Google has strangely opted to post a rundown of the process on X.
Faster local inference right now
Google has released new versions of Gemma 4 models with MTP that you can try today. Google says the MTP drafter can make Gemma models up to three times faster, but the actual gain varies based on the hardware you use. In Google’s testing, the smaller E2B and E4B Gemma models on Pixel phones can run 2.8x and 3.1 times faster, respectively. The much larger Gemma 4 31B on Apple’s M4 silicon gets a 2.5x speed boost with MTP.
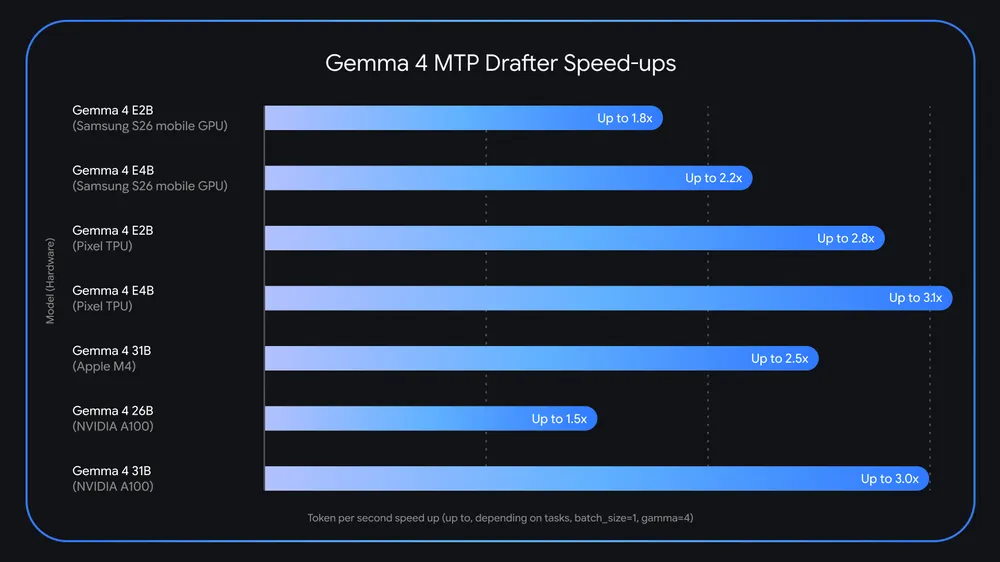
Tokens-per-second speed increases for various hardware configs.
Credit: Google
Tokens-per-second speed increases for various hardware configs. Credit: Google
The company suggests users will find it easier to run the 26B MoE and 31B Dense models on consumer hardware, and mobile devices will enjoy improved battery life when running E2B and E4B models. Because the core Gemma model verifies all the draft tokens, MTP should also result in “zero quality degradation.” That’s not to say every output will be perfect, but the errors common in generative AI systems shouldn’t get any worse with MTP.
You can try speculative decoding in Gemma without too much additional work. The drafters are available under the same Apache 2.0 license as the core Gemma models. The faster transformers are available via MLX, VLLM, SGLang, and Ollama frameworks.
Ryan Whitwam Senior Technology Reporter
Ryan Whitwam is a senior technology reporter at Ars Technica, covering the ways Google, AI, and mobile technology continue to change the world. Over his 20-year career, he’s written for Android Police, ExtremeTech, Wirecutter, NY Times, and more. He has reviewed more phones than most people will ever own. You can him on Bluesky, where you will see photos of his dozens of mechanical keyboards.
Sumber Artikel:
Arstechnica.com


